Plants are enormously important to human welfare because they are a source of food, clothing, housing materials, medicines, and dyes. They replenish the air we breathe, cool the atmosphere that surrounds us, hold our soils in place, and please our senses. They contribute not only to our physical but also to our emotional well-being. In the past, the identification of plant species was the sole domain of taxonomists, botanists, and other professionals who identified unknown plants by comparing them with previously collected specimens or by using books or identification manuals. However, learning about new plants is also an exciting venture for amateur gardeners and outdoor enthusiasts. When anyone hikes, visits public gardens, wanders around campus, or just tours the gardens in the community, the question may arise: what is the name of that plant? Intrigued by a particular herbaceous or woody plant, the person may wonder when it blooms, flower color, size and bloom time, and its cultural requirements. Will it attract pollinators, such as insects and birds? Is it an introduced (exotic) species or is it native to the region or state? Is the plant on the state or federal invasive species list? In other situations people will need to identify the plant species to determine if internal or external exposure would cause harm.
The Internet has provided an immense repository of plant information by a wide variety of private and professional organizations and individuals. With the increasing power of search engines such as Google, people can easily find information about the plants of interest when they can formulate their queries in keywords. Unfortunately, nonprofessional users are unfamiliar with botanical/taxonomic jargon and they may not be able to find suitable keywords to formulate their queries precisely.
The exponential growth of digital cameras and smartphones has created a new opportunity to devise an image-based tool for plant species identification and information-seeking. With digital cameras and smartphones, users can easily take images of their unknown plants and use those plant images as query examples. Such image-based tool for plant species identification and retrieval can enjoy widespread use by backyard botanists, hikers, and school teachers who use the outdoors as a classroom. Professionals can also use this image-based approach for plant species identification to compile data for environmental inventories, monitor biodiversity, or to discover new botanical or horticultural species and cultivars. In the past, some image-based plant identification systems have been developed. Unfortunately, all of these existing systems focus on small-size plant image sets, consider only a small number of well-known plant species, completely ignore the appearances of new plant species, and pay less attention to computational efficiency and vast numbers of plant species. Considering their huge computational costs and learning complexities, the state-of-the-art machine learning techniques are still insufficient for supporting large-scale plant species identification.
2. Research Tasks
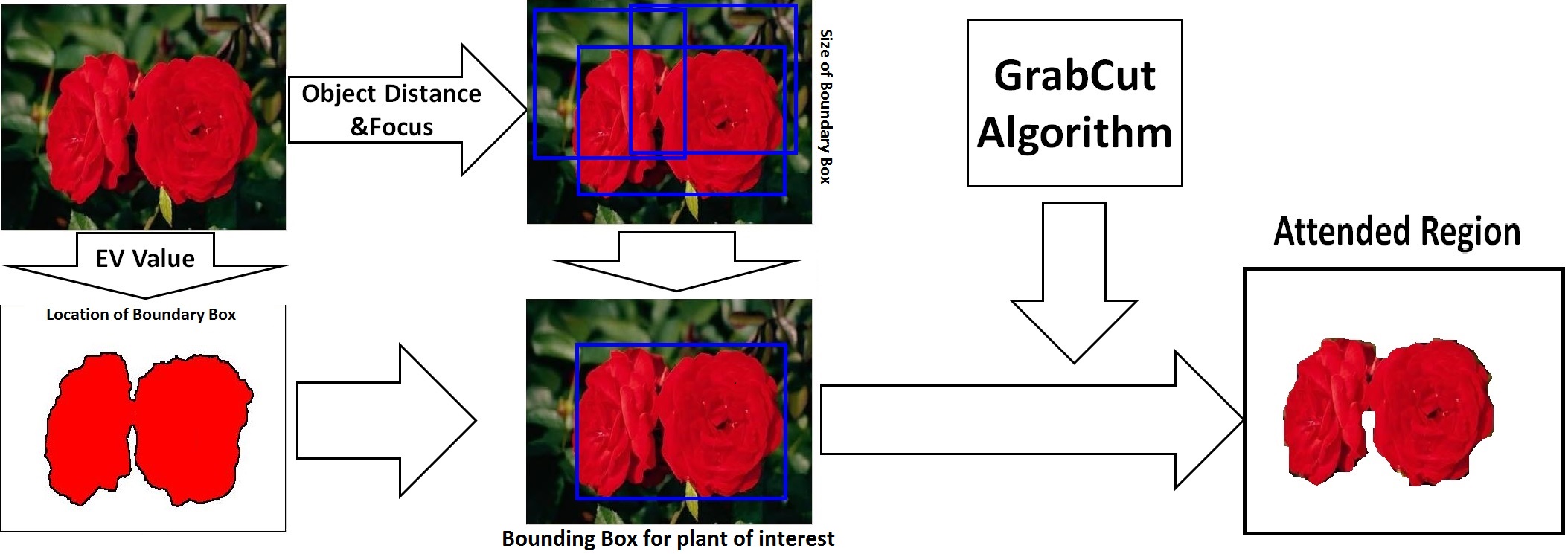
To tackle these challenges, we will develop a scalable learning framework to leverage massive plant images from the Internet to train max-margin tree classifiers over a multi-modal visual hierarchy in parallel. Our scalable learning framework contains the following innovative researches: (a) An automatic algorithm to integrate camera metadata and Grabcut method to separate the plants of interest from complex backgrounds for extracting more discriminative features;
(b) An automatic object-text alignment algorithm to identify more reliable labels (identities) of plant species for massive online plant images;
(c) A multi-modal visual hierarchy for supporting scalable indexing of large-scale plant species;
(d) A scalable learning algorithm to leverage massive plant images from the Internet to train max-margin tree classifiers over the multi-modal visual hierarchy in parallel;
(e) An incremental learning algorithm for handling new plant species more effectively.
3. Automatic Extraction of Plants of Interest
Image-based plant species identification involves a multi-step process. The first step is to separate the plants of interest from complex backgrounds. Unfortunately, automatic image segmentation is usually error-prone and cannot always provide objects of interest accurately. Alternatively, some interactive approaches, such as Grabcut, can accurately extract objects of interest by involving humans to define the bounding boxes for the attended regions. Because of the enormous cost of human involvement, it is impractical to use such interactive segmentation approaches to process large-scale plant images. The plant images are usually taken by people according to their personal intentions. These human-derived plant images significantly differ from the images taken by a fixed surveillance camera or a vision sensor on a mobile robot, i.e., the human photographer's intentions are buried in both image pixels and camera metadata. Thus, the camera metadata can be integrated with the visual content of plant images to achieve more accurate detection of attended regions (i.e., plants of interest). Unfortunately, most existing techniques have completely ignored the camera metadata for attended region detection.
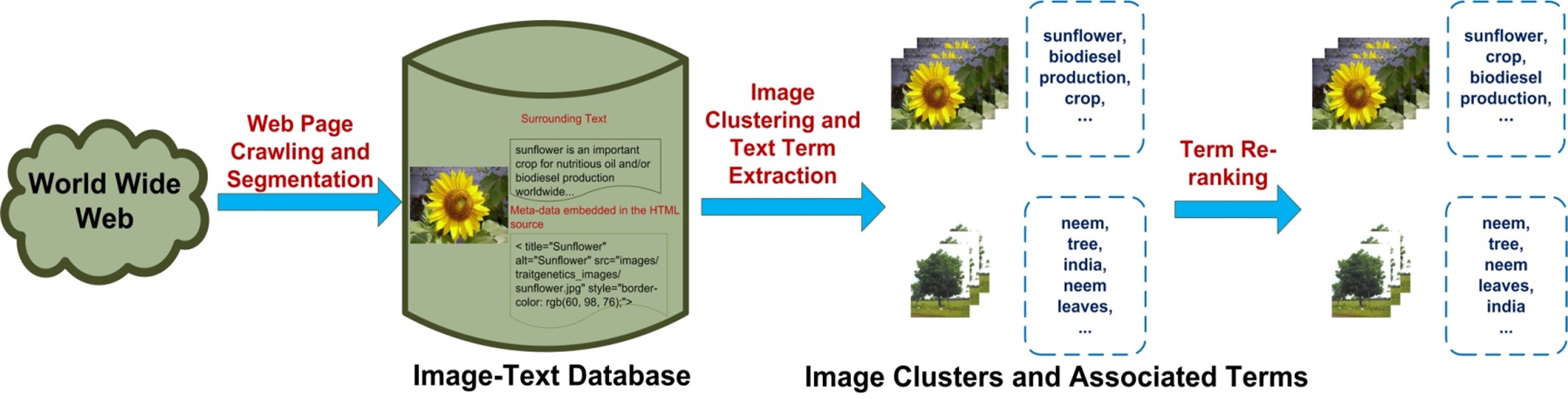
4. Automatic Image-Text Alignment to Generate Large-Scale Training Images
To support image-based plant species identification, we will crawl large-scale plant images from the Internet for classifier training. The web pages associated with online plant images may contain rich vocabulary of text terms: some of them are used to describe the semantics of plant images (i.e., plant species) but most of them are used to describe other types of web content. Thus, there is a {\em huge uncertainty} on the relatedness between the online plant images and their auxiliary text terms, and it is not a trivial task to identify reliable labels (identities) of plant species for massive online plant images, e.g., massive plant images from the Internet are not labeled precisely by their auxiliary text terms and cannot directly be used for classifier training.
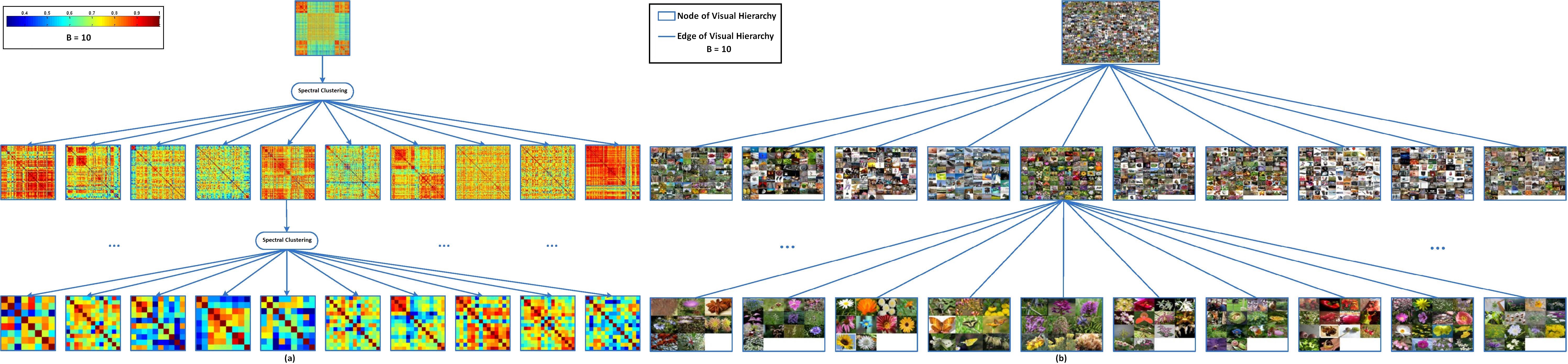
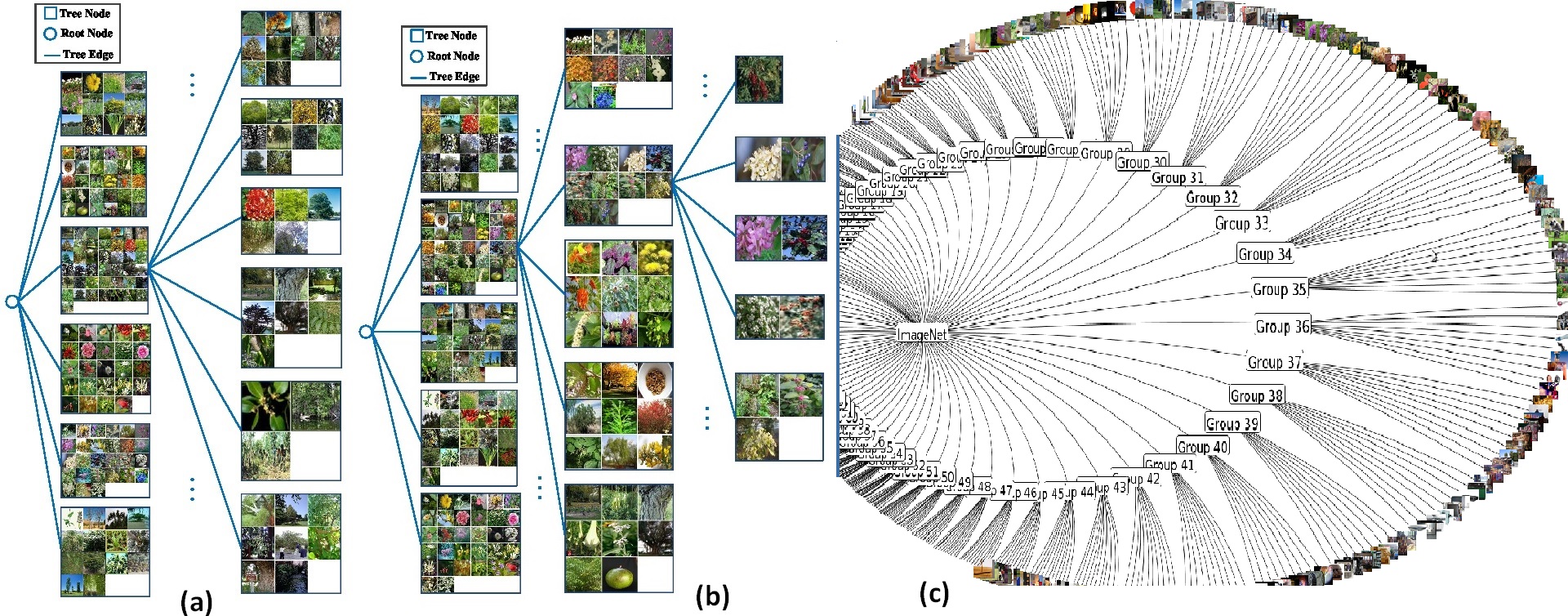
5. Visual Tree Generation for Indexing Large-Scale Plant Species
Two types of tree structures are widely used for image database indexing: (1) semantic hierarchy (concept ontology) that exploits the inter-class semantic correlations in the label space; and (2) visual hierarchy that exploits the inter-class visual correlations in the feature space. The existing approaches for visual hierarchy construction can be categorized into three groups: top-down or bottom-up clustering approach; label tree approach; and joint approach by learning the tree structure and training the node classifiers iteratively. All these existing approaches focus on using one single-modal feature set for visual hierarchy construction, i.e., all the nodes at different levels on the visual hierarchy use the same single-modal feature set for node partitioning and classifier training. On the other hand, plants are extremely diverse in shape, size, structure, texture and color, thus using one single-modal feature set may not be able to separate large-scale plant species effectively.
6. Scalable Learning for Large-Scale Machine Learning
There are currently about 310,000-420,000 known plant species in the world. Considering their huge computational costs and learning complexities, the state-of-the-art machine learning technologies are still not scalable to support large-scale plant species identification. It is also worth noting that distinguishing between large numbers of plant species is inherently more complex than distinguishing between just a few, and large intra-species variations and large inter-species similarities are typical in the botanical domain [1-9]. Because of its low computational cost, the hierarchical approach is very attractive for supporting large-scale plant species identification. Unfortunately, the hierarchical approach may seriously suffer from the problem of inter-level error propagation: the classification errors for the parent nodes will propagate to their child nodes. In addition, the hierarchical approach will bring new challenge: it is naturally difficult to parallelize the process for hierarchical classifier training because huge communications are needed for handling strong inter-level and inter-species or inter-task computational dependencies.
7. Interdisciplinary Knowledge Gap and High-Level Human Guidances
One obstacle for supporting image-based plant species identification is that there is a big interdisciplinary knowledge gap between computer scientists and botanists, e.g., the botanists are not the experts on machine learning and computer vision, thus it could be very difficult for them to understand how the learning approach works and whether it is successful; on the other hand, the computer scientists are not the professionals on botany/horticulture, they should learn from plant morphology to extract more discriminative features for supporting image-based plant species identification. One potential solution of this obstacle is to explicitly visualize the boundaries of the classifiers and their inter-classifier margins, so that computer scientists and botanists can interactively assess the success of the learning approach (i.e., discrimination of various feature subsets and correctness of the classifiers). Some researchers have incorporated multi-dimensional scaling to support data visualization and exploration, but they cannot provide good solutions for what should be visualized simultaneously. Through system interface, computer scientists and botanists may further provide their high-level guidances by manipulating the locations of some plant images interactively (i.e., moving the corresponding data points to their expected locations on the screen). Unfortunately, most existing systems have not provided good solutions for: (1) transforming such high-level human guidances into computer-understandable information (such as additional constraints); and (2) leveraging such information for iterative classifier training.
J. Fan, N. Zhou, J. Peng, L. Gao, ``Hierarchical learning of tree classifiers for large-scale plant species identification", invited paper, IEEE ICSC (IEEE Intl. Conf. on Semantic Computing), Anaheim, CA, 2015.
S. A. Shearer, R.G.Holmes, ``Plant identification using color co-occurrence matrices", Transactions of the ASAE, vol. 33, no. 6, pp.2037-2044, 1990.
J. Hemminga, T. Rathb, ``PA precision agriculture: Computer-vision-based weed identification under field conditions using controlled lighting", Journal of Agricultural Engineering Research, vol. 78, no. 3, pp.233-243, 2001.
S. Abbasi, F. Mokhtarian, and J. Kittler, ``Reliable classification of chrysanthemum leaves through curvature scale space", Scale-Space Theory in Computer Vision, pages 284-295, 1997.
G. Agarwal, P. Belhumeur, S. Feiner, D. Jacobs, W.J. Kress, R. Ramamoorthi, N.A. Bourg, N. Dixit, H. Ling, D. Mahajan, R. Rusty, S. Sameer, S. Kalyan, W. Sean, ``First steps toward an electronic field guide for plants", Taxon, pp. 597-610, 2006.
P.N. Belhumeur, D. Chen, S. Feiner, D. W. Jacobs, W. J. Kress, H. Ling, I. Lopez, R. Ramamoorthi, S. Sheorey, S. White, L. Zhang, ``Searching the world?s herbaria: A system for visual identification of plant species", ECCV, pp. 116-129, 2008.
N. Kumar, P.N. Belhumeur, A. Biswas, D. W. Jacobs, W. J. Kress, I. C. Lopez, and J. V. Soares, "Leafsnap: A computer vision system for automatic plant species identification", ECCV, pp. 502-516, 2012.
F. Mokhtarian and S. Abbasi, ``Matching shapes with self-intersections: Application to leaf classification", IEEE Trans. on IP, vol. 13, no.5, pp.653-661, 2004.
J.C. Neto, G.E. Meyer, D.D. Jones, and A.K. Samal, ``Plant species identification using elliptic fourier leaf shape analysis", Computers and Electronics in Agriculture, vol.50, no.2, pp.121-134, 2006.
J. Harnsomburana, J. Green, A. Barb, M. Schaeffer, L. Vincent, C. Shyu, ``Computable visually observed phenotype ontological framework for plants", BMC Bioinformatics, 2011.
H. Goeau, P. Bonnet, A. Joly, I. Yahiaoui, D. Barthelemy, N. Boujemaa, J. Molino, ``The ImageCLEF 2012 plant identification tasks", Technical Report, INRIA, 2012.
M. Chopra, ``TreeID: An image recognition system for plant species identification", Tech. report, Stanford University.
G.E. Meyer, T. Hindman, K. Laksmi, ``Machine vision detection parameters for plant species identification", SPIE, 1998.
V. Trifa, A. Kirschel, C. Taylor, E. Vallejo, ``Automated species recognition of antbirds in a Mexican rainforest using hidden Markov models", The Journal of The Associate Society of America, vol.123, 2008.
R. Hu, W. Jia, H. Ling, D. Huang, ``Multiscale distance matrix for fast plant leaf recognition", IEEE Trans. IP, vol.21, no.11, pp.4667-4672, 2012.
T. Saitoh, T. Kaneko, ``Automatic recognition of wild flowers", IEEE ICPR, 2000.
M.E. Nilsback and A. Zisserman, ``A visual vocabulary for flower classification", IEEE CVPR, 2006.
M.E. Nilsback and A. Zisserman, ``Delving deeper into the whorl of flower segmentation", Image and Vision Computing, vol.28, no.6, pp.1049-1062, 2010.
J. Cope, D. Corney, J. Clark, P. Remagnino, P. Wilkin, ``Plant species identification using digital morphometrics: A review", Expert Systems with Applications, vol.39, pp.7562-7573, 2012.
 1. Research Motivation:
1. Research Motivation:

 If we know what we were doing, it wouldn't be research, would it?
---Albert Einstein(1879-1955)---
If we know what we were doing, it wouldn't be research, would it?
---Albert Einstein(1879-1955)---